
Для чего нужны индексы? У индексов таблиц в РСУБД два назначения – используются для эффективного поиска и для сортировки.
Сегодня хочу рассказать о том, каким образом устроены индексы в реляционных базах данных, в частности в Microsoft SQL Server. Сразу оговорюсь, что этот материал для начального уровня, здесь я не буду рассматривать структуру B-Tree и многие глубокие вещи. В этом обзоре предлагаю на начальном уровне разобраться с базовыми понятиями индексов. В обзоре будут примеры алгоритмов, поэтому у тебя, для понимания, ты должен знать, что такое сортировка, разница в поиске в сортированном и несортированном массивах. В этом обзоре я буду проводить ассоциации со структурами и массивами – как аналог таблиц в реляционных СУБД.
Итак – поехали.
Предлагаю рассмотрение начать с простой таблицы – сотрудники. Нам этой таблицы более чем достаточно для разбора материала.
create table employees
(
ID int not null identity, -- суррогатный первичный ключ
TabNo varchar(20) not null -- табельный номер может содержать только цифры и тире
check (TabNo not like '%[^0-9,^-]%'),
EmploymentDate date not null, -- дата трудоустройства
FirstName nvarchar(50) not null, -- Имя
LastName nvarchar(50) not null, -- Фамилия
MiddleName nvarchar(50) null, -- отчество
FullName as LastName+' '+FirstName+isnull(' '+MiddleName,''), -- ФИО
Gender char(1) not null -- пол
check (Gender in ('F','M')),
BirthDay date not null -- дата рождения
)
insert employees values
('000-001','2015-01-20','Андрей','Иванов','Сидорович','M','1980-05-05'),
('000-002','2015-01-20','Григорий','Петров','Сидорович','M','1981-06-05'),
('000-003','2015-02-12','Ольга','Иванова','Алексеевна','F','1985-01-25'),
('000-004','2015-03-02','Андрей','Иванов','Сидорович','M','1970-05-05'),
('000-005','2015-03-05','Сергей','Сидоров','Сидорович','M','1975-05-05'),
('000-006','2015-03-07','Сидр','Козлов','Сидорович','M','1983-05-05'),
('000-007','2015-03-21','Андрей','Баранов','Сидорович','M','1988-05-07'),
('000-008','2015-03-21','Василий','Медведев','Сидорович','M','1965-05-05'),
('000-009','2015-03-21','Петр','Баранов','Сидорович','M','1978-12-12'),
('000-010','2015-03-21','Абдула','Мамедов',null,'M','1969-11-11')
В процедурном языке программирования в паскаль или си – аналог таблицы — это массив элементом которого является структура с теми же полями что и наша таблица.
struct pk_employee
{
int ID;
char TabNo[20];
char EmploymentDate[10];
char FirstName[50];
char LastName[50];
char MiddleName[50];
char Gender;
char BirthDay[20];
};
pk_employee employee[Много_строк];
Этот массив не отсортирован, поэтому любая операция извлечения данных (select … from employees) с условием или без такового будет сопровождаться перебором всех элементов нашего массива, даже если нам нужно будет элемент по ID у нас нет индекса и SQL Server пока ничего не знает сколько раз этот элемент будет встречаться, поэтому всегда будет полный перебор. Предлагаю выполнить запрос с условием по ID и без условия и сравнить планы запросов
select * from employees
select * from employees where ID = 4
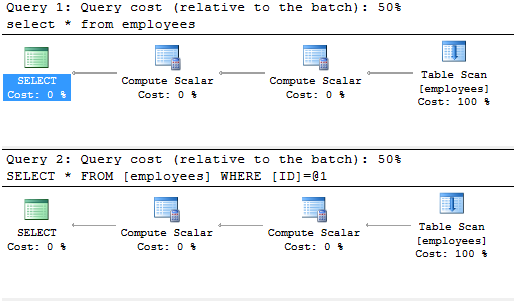
Видна абсолютная идентичность планов как по стоимости (50% верхний от общего плана и половина так же 2й запрос нижний с условием). В плане запроса мы видим, что 100% от всего запроса занимает Table Scan – сканирование таблицы – это и есть полный перебор элементов массива.
А что бы было если бы наш массив был бы отсортированным по уникальному полю ID? Ты же прекрасно понимаешь, что можно было бы не полным перебором найти нужный элемент, например, половинным делением или другим алгоритмом?
Вообще, когда таблица не отсортирована, как в нашем случае – данные хранятся в «куче (heap)». Но можно упорядочить данные по выбранному критерию, по любому набору полей в нашей таблице, например по – LastName,FirstName,MiddleName или по ID и дать команду SQL Server что бы он поддерживал нужную нам последовательность – порядок данных в таблице. Эта команда – создать кластерный индекс. Кластерный индекс – это альтернатива куче. В куче данные лежат хаотично – в таком порядке в каком их положили в БД (со временем, после дефрагментации, сжатия файлов БД – порядок данных в куче изменится), а более точно – имея кучу – SQL Server не следит за упорядочиванием данных в таблице. Но если мы создадим кластерный индекс на таблице – сервер будет всегда поддерживать данные в том порядке в каком мы указали в кластерном индексе. Ну и стоит упомянуть очевидное – в таблице может быть только один кластерный индекс, или его совсем может не быть, в таблице вместо кластерного индекса – куча.
Предлагаю создать кластерный индекс по ФИО и первичный ключ (не кластерный индекс) по ID.
create clustered index ix_Employees_FIO on employees (LastName,FirstName,MiddleName);
alter table employees add constraint pk_employees primary key nonclustered (ID);
Проверим – какие индексы у нас есть на нашей таблице: exec sp_helpindex 'employees'

В описании индекса (index_description) видно, что индекс pk_employees – уникальный. Разница в уникальном и не уникальном индексе почти отсутствует, за исключением, когда мы ищем в уникальном индексе строки – при нахождении одной строки – можно остановиться и выдать результат, если мы создадим неуникальный индекс и будем по нему искать – то поиск будет изначально строки с требуемым условием, а после сканирование рядом находящихся строк. Например, в нашем кластерном неуникальном индексе если мы зададим условие ФИО – «Иванов Андрей Сидорович» - мы получим 2 строки – найдется сначала одна строка, и далее рядом лежащие строки, подпадающие по условие.
Заново выполним запросы, которые уже смотрели:
select * from employees
select * from employees where ID = 4
select ID from employees where ID = 4
Посмотрим, что за данные вывел наш запрос и сравним планы запросов:
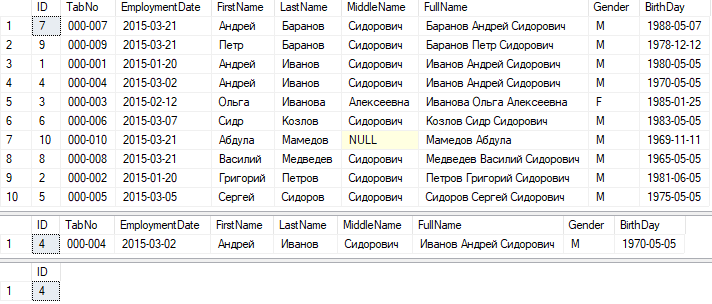
Здесь, если ты заметил, простой селект из таблицы всех полей вывел сортированный результат по полям кластерного индекса – Фамилия, Имя, Отчество. После создания кластерного индекса данные в таблице стали именно по этим полям упорядочены, т.е. сначала по фамилии – Баранов, Иванов, после внутри одинаковых фамилий порядок по 2му полю по имени – Баранов Андрей, а после Баранов Петр, и уже если совпадают и Фамилия, и Имя, упорядочивание поддерживается по следующему, в нашем случае последнему 3му полю – Отчеству.
Ну и здесь стоит отметить, что наш кластерный индекс – составной. Составной индекс, это когда тело индекса (список полей) состоит из 2х и более полей.
Теперь разбираемся что нам выдал план запроса
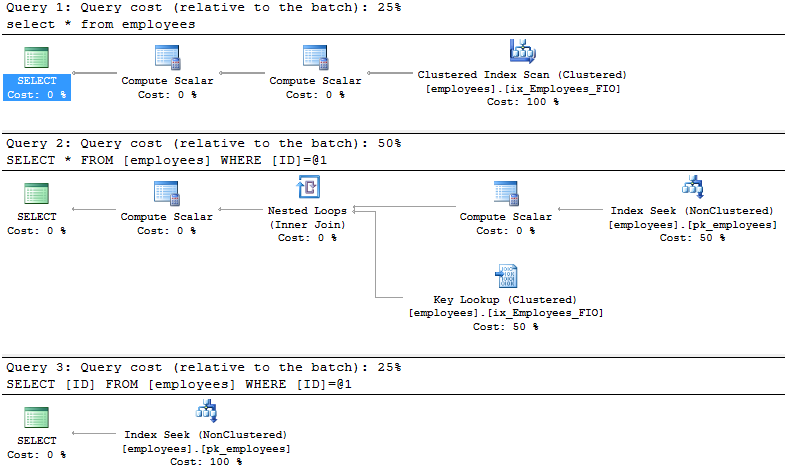
Первый запрос – select * from employees
выдает нам сканирование кластерного индекса, ну и как мы видим результат выдал в отсортированном виде в том в каком задали тело индекса. Это частный случай. На самом деле наличие кластерного индекса не гарантирует нам результат отсортированным, если мы явно не зададим нужный order by. Это может случиться, например, когда данных в таблице много и они не умещаются в оперативную память сервера, а такой запрос выполняется несколькими клиентам в разный промежуток времени. И, например, на сервере 1Гб оперативной памяти, а таблица наша 10гб размером. Такой запрос за 10 раз считает в оперативную память по гигабайту и выдаст клиенту результат. И когда клиент в следующий раз без order by выполнит этот же запрос – мы понимаем, что сортировка не требуется и сервер вполне можем сначала отдать то что уже в кэше (в оперативной памяти – последний 1гб), а после заново просканировать и выдать недостающие данные.
Третий запрос – select ID from employees where ID = 4
Выдает нам поиск в индексе – это практически самый быстрый поиск с помощью индекса, в плане только 2 элемента – поиск и вывод.
А вот второй запрос намного сложнее третьего - select * from employees where ID = 4
И давай разберемся что это все означает и причины возникновения дополнительных элементов в плане запроса.
Изначально мы видим поиск по не кластерному индексу pk_employees – это операция нахождения нужных строк по заданному условию – where ID = 4. Ровно такая же команда в 3м плане запроса.
Далее Compute Scalar – мы выводим наше вычисляемое поле FullName – поле вычисляется «на лету» при запросе.
Ну и Key Lookup – операция достаточно тяжелая. Возникает из-за того, что в нашем не кластерном индексе указано только единственное поле ID, а в запросе мы хотим видеть все поля и те, которых нет в не кластерном индексе. И именно из-за этой причины сервер достает оставшиеся данные из кластерного индекса (ну или из кучи бы доставал, если бы не было кластерного индекса).
Вообще не кластерный индекс — это тот же отсортированный массив с телом индекса (что мы указали при объявлении) плюс дополнительная ссылка на страницу где аналогичная строка в куче если нет кластерного индекса или при наличии кластерного индекса – хранится в каждом строке не кластерного индекса не ссылка а тело кластерного индекса.
struct ix_Employee_FIO
{
int ID;
char TabNo[20];
char EmploymentDate[10];
char FirstName[50];
char LastName[50];
char MiddleName[50];
char Gender;
char BirthDay[20];
};
ix_Employee_FIO employee[Много_Строк];
// в нашем случае будет использоваться такая структура с кластерным индексом
struct pk_Employee
{
int ID;
char FirstName[50];
char LastName[50];
char MiddleName[50]; int InvisibleCounter; };
// а вот если бы не было кластерного индекса, то структура была бы такой
struct pk_Employee
{
int ID;
ix_Employee_FIO *Lookup;
};
Т.е. в нашем случае мы создали индекс pk_employee с полем (ID) уникальный и автоматически в индексе присутствует 3 поля нашего кластерного индекса. И так как наш кластерный индекс не уникальный, то однозначно идентифицировать по телу кластерного индекса мы не можем, поэтому SQL Server так же хранит не видимый для отображения поле счетчик 4х байтный, чтобы однозначно идентифицировать нужную нам строку, когда это требуется – для операции Lookup.
Операция Lookup это по сути запрос к кластерному индексу что бы в результате получить те поля которых нет в теле не кластерного индекса. А операция Nested Loop – это операция связи таблиц ну при Lookup связь строк не кластерного индекса с кластерным (или кучи если бы такая была у нас).
Вообще наш кластерный индекс весьма показателен с позиции какие кластерные индексы делать не нужно. Мы захотим сделать несколько не кластерных индексов в дальнейшем: по дате, по табельному номеру, по каким-то коротким полям и при этом во всех индексах будет дополнительно дублироваться Фамилия Имя Отчество – тело кластерного индекса плюс счетчик, в среднем это дополнительные до 300 байт к каждой строке (150 символов максимум и юникод один символ 2 байта) не кластерного индекса. Именно по этой причине рекомендуется тело кластерного индекса делать коротким и уникальным – идеальным претендентом на кластерный индекс это первичный ключ – поле ID – 4 байта всего против 48 байтов в нашей структуре с приведенными данными в среднем.
Теперь предлагаю рассмотреть несколько запросов для поиска по индексу.
Создадим новые индексы.
create nonclustered index ix_Employees_BirthDay on employees (BirthDay,EmploymentDate)
include (ID,TabNo,FullName,Gender);
create nonclustered index ix_Employees_EmploymentDate on employees (EmploymentDate,BirthDay)
include (ID,TabNo,Gender);
Здесь, помимо тела индекса я добавил предложение include – в котором перечислил все остальные поля таблицы, которых нет в теле индекса этого и кластерного индексов, что бы избегать операции lookup – эту операцию мы рассмотрели выше.
Выполним запросы и посмотрим планы:
select * from employees with(index=ix_Employees_BirthDay)
where BirthDay >= '1980-01-01' and EmploymentDate >= '2015-02-01'
select * from employees with(index=ix_Employees_EmploymentDate)
where BirthDay >= '1980-01-01' and EmploymentDate >= '2015-02-01'
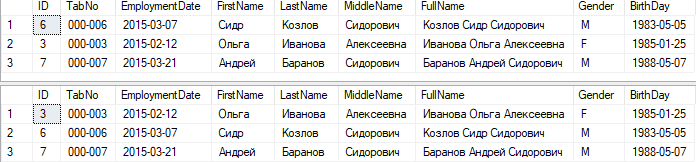
Видно, что разные сортировки при использовании разных индексов. По планам – по стоимости и структуре – планы идентичны.
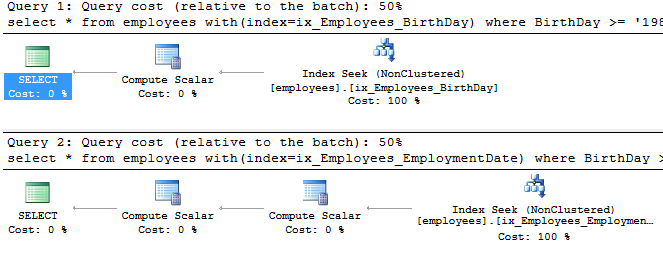
За исключением, что в 1м индексе мы вычисляемое поле FullName включили в индекс, тем самым план стал чуть проще нежели во 2м запросе.
Вообще, как мы помним логическое «И» коммутативно – от перестановки слагаемых сумма (результат логического «И») не меняется, и для данного запроса можно использовать любой из этих двух индексов.
А вот для запросов:
select * from employees
where BirthDay >= '1980-01-01'
select * from employees
where EmploymentDate <= '2015-02-01'

Требуются разные индексы. Т.е. в обоих индексах есть поле BirthDay и EmploymentDate, но здесь важен порядок. В ix_Emplyees_BirthDay сортировка сначала по BirthDay и внутри повторений по EmploymentDate, в другом индексе поля поменяны местами, и соответственно именно поэтому индекс выбирается другой.
Если в условии есть поле, которое первое в теле индекса, то имеет смысл выбирать этот индекс для выборки, если первое, второе, третье – индекс сработает еще эффективнее.
Ну и напоследок предлагаю рассмотреть еще один индекс:
create nonclustered index ix_Employees_FullName on employees (FullName)
include (ID,TabNo,Gender,EmploymentDate,BirthDay) where Gender = 'F';
Здесь я просто хочу показать то, что в теле индекса могут быть вычисляемые поля, что полезно, когда эти поля используются в условиях и сортировках. И мы видим, что можно индекс строить не по всем строкам, а фильтровать по условиям. Иногда это удобно, например, меньше дискового пространства и в нашем случае поиск по мужчинам не имеет большого смысла их большинство – проще просканировать кластерный индекс, а женщина всего одна.
Надеюсь данная статья помогла устранить пробелы в знании об индексах.